[프로젝트 구성 및 의존성 설정]
스프링 배치 초기화 설정 클래스
1.BatchAutoConfiguration
-스프링 배치가 초기화 될 때 자동으로 실행되는 설정 클래스
-Job을 수행하는 JobLauncherApplicationRunner 빈을 생성
2.SimpleBatchConfiguration
-JobBuilderFactory와 StepBuilderFactory 생성
-스프링 배치의 주요 구성 요소 생성 - 프록시 객체로 생성됨
3.BatchConfigurerConfiguration
3-1.BasicBatchConfigurer
-simpleBatchConfiguration에서 생성한 프록시 객체의 실제 대상 객체를 생성하는 설정 클래스
-빈으로 의존성 주입 받아서 주요 객체들을 참조해서 사용할 수 있다.
3-2.JpaBatchConfigurer
-JPA관련 객체를 생성하는 설정 클래스
3-3.(*)사용자 정의 BatchConfigurer 인터페이스를 구현하여 사용할 수 있음
설정 클래스 순서
@EnableBatchProcessing -> SimpleBatchConfiguration -> BatchConfigurerConfiguration(BasicBatchConfigurer, JpaBatchConfigurer) -> BatchAutoConfiguration
BatchAutoConfiguration 에서 JobLauncherApplicationRunner ruuner가 이 클래스가 우리가 만든 잡을 실행시키는 클래스입니다.
*설정 클래스는 @Configuration 어노테이션을 클래스 선언부 앞에 추가하면 된다. 또한 특정 타입을 리턴하는 메서드를 만들고 @Bean 어노테이션을 붙여주면 자동으로 해당 타입의 Bean이 생성된다.
@Bean 어노테이션의 세부 내용은 다음과 같다.
- @Configuration 설정된 클래스의 메서드에서 사용가능하다.
- 메서드 리턴 객체를 IoC의 Bean으로 등록한다.
- Bean의 이름은 기본적으로 메서드 이름으로 등록된다.
- @Bean(name="name")으로 변경할 수 있다.
- @Scope를 통해 객체 생성을 조정할 수 있다.
- @Component 어노테이션을 통해 @Configuration 없이도 Bean을 등록할 수 있다.
- Bean에 init(), destory() 등 라이프 사이클 메서드를 추가한 후 @Bean에 지정할 수 있다.
- @Configuration 애노테이션을 보면 이 애노테이션도 @Component를 사용하기 때문에 @ComponentScan의 스캔
대상이되고 그에 따라 빈 설정파일이 읽힐 때 그 안에 정의한 빈들이 IoC컨테이너에 등록 된다.
[Hello Spring Batch 시작하기]
1.@Configuration 선언
-하나의 배치 job을 정의하고 빈 설정
2.JobBuilderFactory
-Job을 생성하는 빌더 픽토리
3.StepBuilderFactory
-Step을 생성하는 빌더 팩토리
4.Job
-helloJob이름으로 Job 생성
ex)
@Bean
public Job helloJob() {
return jobBuilderFactory.get('helloJob') //Job 생성
.start(helloStep())
.build(); // build하면 job은 인터페이스인데요. (기본적으로 제공하는 job의 구현체) 구현체의 job 객체가 생성된다.
}
5.Step
-helloStep 이름으로 Step 생성
6.tasklet
-Step 안에서 단일 테스크로 수행되는 로직 구현
7. Job 구동 -> Step을 실행 -> Taskelt을 실행
Job이 구동되면 Step을 실행하고 Step이 구동되면 Taskelt을 실행하도록 설정함
JOB - 일, 일감
STEP - 일의 항목, 단계
TASKLET - 작업내용(비즈니스 로직)
Job이 생성되면 Job은 기본적으로 Step을 포함하고 있습니다.
필수요소로 Step을 갖고 있어야 한다.
Step도 Job을 만들때랑 비슷하다.
Step안에는 tasklet을 둘 수 있다.
step에서는 기본적으로 tasklet이 무한 반복한다.
return null이면 한번 실행되고 종료된다.
null과 같은 상태 값이 RepeatStatus.FINISHED입니다.
simpleJob이 스프링이 배치에서 만든 구현체입니다.
[DB 스키마 생성 및 이해(1)]
내부적으로 Job이 구동되면 Job의 실행정보 및 상태정보를 담고 있는 JobExecution이 실행되고
Step이 구동 되면 StepExecution이 실행 된다.
이 정보들이 데이터베이스에 저장된다.
Job과 Step의 상태정보를 저장할 수 있는 테이블(스키마)을 스프링 배치에서 기본적으로 제공한다.
스크립트를 가지고 테이블을 생성해서 메타 데이터(실행정보, 상태 정보)를 저장하면 된다.
이것들을 통해 과거, 현재의 실행에 대한 세세한 정보, 실행에 대한 성공과 실패 여부 등을 일목요연하게 관리함으로서 배치운용에 있어 리스크 발생시 빠른 대처 가능합니다.
DB와 연동할 경우 필수적으로 메타 테이블이 생성 되어야 한다.
-스키마 생성 설정
수동생성 - 쿼리 복사 후 직접 실행
자동생성 - spring.batch.jdbc.initialize-schema 설정
1. ALWAYS
-스크립트 생성
2. EMBEDDED : 내장 DB일 때만 실행되며 스키마가 자동 생성됨, 기본값
3. NEVER
-스크립트 항상 실행 안함
-내장 DB일 경우 스크립트가 생성이 안되기 때문에 오류 발생
-운영에서 수동으로 스크립트 생성 후 설정하는 것을 권장
Job관련 테이블
1. BATCH_JOB_INSTANCE
-Job이 실행될 때 JobInstance 정보가 저장되며 job_name과 job_key를 키로 하여 하나의 데이터가 저장
-동일한 job_name과 job_key로 중복 저장될 수 없다.
2. BATCH_JOB_EXECUTION
-Job의 실행정보가 저장되며 Job 생성, 종료 시간, 실행상태, 메시지 등을 관리
3. BATCH_JOB_EXECUTION_PARAMS
-Job과 함께 실행되는 JobParameter 정보를 저장
4. BATCH_JOB_EXECUTION_CONTEXT
-Job의 실행동안 여러가지 상태정보, 공유 데이터를 직렬화(Json 형식)해서 저장
-Step 간 서로 공유 가능함
Step 관련 테이블
1.BATCH_STEP_EXECUTION
-Step의 실행정보가 저장되며 생성, 시작, 종료 시간, 실행상태, 메시지 등을 관리
2. BATCH_STEP_EXECUTION_CONTEXT
-Step의 실행동안 여러가지 상태정보, 공유 데이터를 직렬화(Json 형식) 해서 저장
-Step 별로 저장되며 Step 간 서로 공유할 수 없음

[스프링배치 도메인 이해 - Job]
1. 기본개념
-배치 계층 구조에서 가장 상위에 있는 개념으로서 하나의 배치작업 자체를 의미함
-"API 서버의 접속 로그 데이터를 통계 서버로 옮기는 배치"인 Job 자체를 의미한다.
-Job Configuration을 통해 생성되는 객체 단위로서 배치작업을 어떻게 구성하고 실행할 것인지 전체적으로 설정하고 명세해놓은 객체
-배치 Job을 구성하기 위한 최상위 인터페이스이며 스프링 배치가 기본 구현체를 제공한다.
(그래서 우리가 그 구현체를 생성해서 즉, 빈으로 생성해서 실행시키는 구조이다.)
-여러 Step을 퐇마하고 있는 컨테이너로서 반드시 한개 이상의 Step으로 구성해야 함
2. 기본 구현체
-SimpleJob
-순차적으로 Step을 실행시키는 Job
-모든 Job에서 유용하게 사용할 수 있는 표준 기능을 갖고 있음
-FlowJob
-특정한 조건과 흐름에 따라 Step을 구성하여 실행시키는 Job
-Flow객체를 실행시켜서 작업을 진행함
(SimpleJob은 Step을 품고 있고, FlowJob은 Flow를 품고 있습니다. 그래서 각각에 품고 있는 Step과 Flow으롤 통해
우리가 구현한 비지니스로직을 실행시킨다.)
JobLauncher: Job을 실행시키는 역할을 한다. 이떄 잡을 실행시킬 떄 필요한 인자가 잡이라는 객체, 그리고 JobParamters라는 도메인 객체 이 2개의 인자를 가지고 실행을 시킨다.
Job을 구성할 때 스탭의 갯수는 상관없다.
Job은 하나의 도메인 객체이고, 인터페이스로 제공되지만(기본 구현체가 제공된다고 했죠? SimpleJob)
SimpleJob은 Step을 포함하고 있는 일종의 컨테이너 역할을 한다.
내부에 steps라는 리스트 변수를 가지고 있고, 리스트 변수에 step을 품고 있으면서 Job이 구동이되면 순차적으로 Step을 실행시키는 구조로 되어 있습니다.
Job은 하나의 명세서이고 설계도이다. Step을 포함하고 있는 컨테이너역할을 한다.

설정이 끝나고 나면 실행을 시켜야 하는데 실행을 시킬때는 수동으로 시킬 수도 있고, 스프링 부트 같은 경우에는
우리가 설정한 SimpleJob을 자동으로 실행을 시켜줍니다.

BatchAutoConfiguration에서 JobLauncherApplicationRunner가 있습니다.
이게 JobLauncher라는 클래스를 가지고 Job을 실행시키는 클래스입니다.
SimpleJob은 StepHandler라는 클래스를 통해서 스탭을 실행시킵니다.
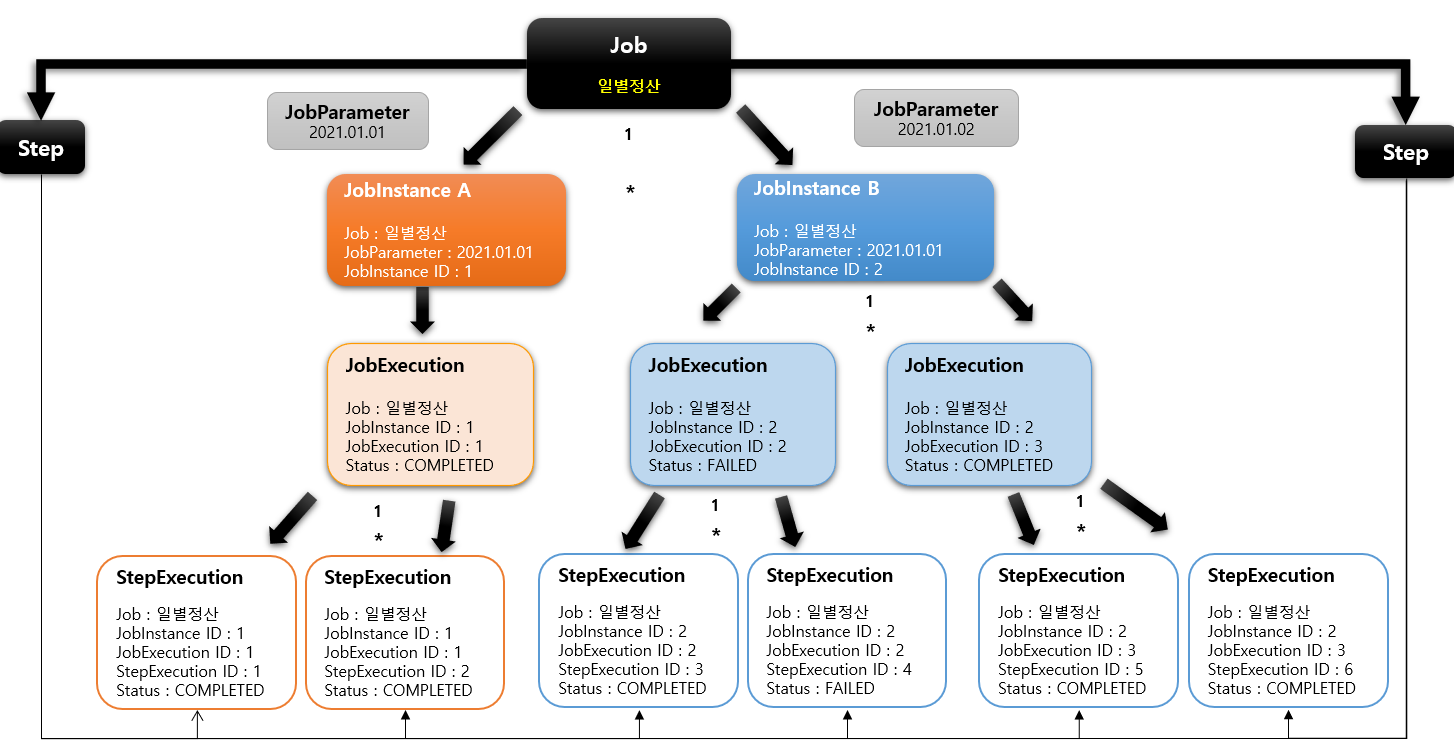
[스프링배치 도메인 이해 - JobInstance]
1. 기본개념
-Job이 실행될 때 생성되는 Job의 논리적 실행 단위 객체로서 고유하게 식별 가능한 작업 실행을 나타냄
-Job의 설정과 구성은 동일하지만 Job이 실행되는 시점에 처리하는 내용은 다르기 때문에 Job의 실행을 구분해야 함
-예를 들어 하루에 한번 씩 배치 Job이 실행된다면 매일 실행되는 각각의 Job을 JobInstance로 표현합니다.
-JobInstance 생성 및 실행
-처음 시작하는 Job+JobParameter일 경우 새로운 JobInstance 생성
-이전과 동일한 Job_JobParameter으로 실행 할 경우 이미 존재하는 JobInstance리턴
-내부적으로 JobName+JobKey(JobParametes의 해시값)를 가지고 JobInstance 객체를 얻음
-Job과는 1:M 관계
2. BATCH_JOB_INSTANCE 테이블과 매핑
-JOB_NAME(job)과 JOB_KEY(JobParameter 해시값)가 동일한 데이터는 중복해서 저장할 수 없음
*Job이랑 JobInstance가 뭐가 다른지 의문이 들 수가 있습니다.
실행관점에서 Job, Step, Flow는 실제로 배치 잡을 실행하고 구성하기 위한 용도이고
이런 Job, Step, Flow가 실행되고 수행이 되면 그 단계마다 메타데이터(Job의 실행, 상태정보, Step의 실행, 상태정보)를
데이터베이스에 저장하기 위한 용도로 그 시점마다 생성되는 것들이 JobInstance, JobExecution, JobParameter 등의 도메인들이다.
[스프링배치 도메인 이해 - JobParameter]
1. 기본개념
-Job을 실힝핼 때 함께 포함되어 사용되는 파라미터를 가진 도메인 객체
-하나의 Job에 존재할 수 있는 여러개의 JobInstance를 구분하기 위한 용도
-JobParameters와 JobInstance는 1:1관계
*JobParameter에는 key와 value로 구성되어 있는 Map을 포함하고 있다.
이 값들이 데이터베이스에 저장된다.
2. 생성 및 바인딩
-어플리케이션 실행 시 주입
-java -jar LogBatch.jar requestDate=20210101
-코드로 생성
-JobParameterBuilder, DefaultJobParametersConverter
-SpEL이용
-@Value("#{jobParameter[requestDate]}"), @JobScope, @StepScope 선언 필수
3. BATCH_JOB_EXECUTION_PARAM 테이블과 매핑
- JOB_EXECUTION과 1:M의 관계

[스프링배치 도메인 이해 - JobExecution]
1. 기본 개념
-JobInstance에 대한 한번의 시도를 의미하는 객체로서 Job 실행 중에 발생한 정보들을 저장하고 있는 객체
-시작시간, 종료시간, 상태(시작됨,완료,실패),종료상태의 속성을 가짐
-JobInstance 과의 관계
-JobExecution은 'FAILED' 또는 'COMPLETED' 등의 Job의 실행 결과 상태를 가지고 있음
-JobExecution의 실행 상태 결과가 'COMPLETED'면 JobInstance 실행이 완료된 것으로 간주해서 재 실행이 불가함
-JobExecution의 실행 상태 결과가 'FAILED'면 JobInstance 실행이 완료되지 않은 것으로 간주해서 재실해이 가능함
-JobParameter 가 동일한 값으로 Job을 실행할지라도 JobInstance를 계속 실행할 수 있음
-JobExecution의 싫애 상태 결과가 'COMPLETED'될 때까지 하나의 JobInstance 내에서 여러 번의 시도가 생길 수 있 음
2. BATCH_JOB_EXECUTION 테이블과 매핑
-JobInstance와 JobExecution는 1:M의 관계로서 JobInstance에 대한 성공/실패의 내역을 가지고 있음

[스프링배치 도메인 이해 - StepExecution]
1. 기본 개념
-Step에 대한 한번의 시도를 의미하는 객체로서 Step 실행 중에 발생한 정보들을 젖아하고 있는 객체
-시작시간, 종료시간, 상태(시작됨,완료,실패), commit count, rollback count 등의 속성을 가짐
-Step이 매번 시도될 때마다 생성되며 각 Step 별로 생성된다.
-Job이 재시작하더라도 이미 성공적이 완료된 Step은 재 실행되지 않고 실패한 Step만 실행된다.
-이전 단계 Step이 실패해서 현재 Step을 실행하지 않았다면 StepExecution을 생성하지 않는다. Step이 실제로
시작됐을 때만 StepExecution을 생성한다.
-JobExecution과의 관계
-Step의 StepExecution이 모두 정상적으로 완료 되어야 JobExecution이 정상적으로 완료된다.
-Step의 StepExecution 중 하나라도 실패하면 Jo bExecution은 실패한다.
2. BATCH_STEP_EXECUTION 테이블과 매핑
-JobExecution와 StepExecution는 1:M의 관계
-하나의 Job에 여러 개의 Step으로 구성했을 경우 각 StepExecution은 하나의 JobExecution을 부모로 가진다.
*BATCH_JOB_EXECUTION은 성공을 하든 실패를 하든 JOB이 다시 실행만 한다면 매번 생성되는 객체입니다.
[스프링배치 도메인 이해 - StepContribution]
1. 기본개념
-청크 프로세스의 변경 사항을 버퍼링 한 후 StepExecution 상태를 업데이트하는 도메인 객체
-청크 커밋 직전에 StepExecution의 apply 메서드를 호출하여 상태를 업데이트함
(StepContribution이 가지고 있는 속성 값들을 apply 메서드를 호출해서 StepExecution에 업데이트 한다.)
-ExitStatus의 기본 종료코드 외 사용자 정의 종료코드를 생성해서 적용할 수 있음
*Tasklet은 넓은 범위에서 보면 청크 프로세스라고 할 수 있습니다.
*StepContribution이 StepExecution에 어떤 절차를 통해서 어떤 시점에 내용들을 업데이트 하는지 흐름들을 보자.

StepExecution클래스 내부에 StepContribution 객체를 생성하는 로직이 있다.
*TaskletStep이 ChunkOrientedTasklet이라는 Tasklet을 구현한 구현체입니다.
다만, chunk기반의 프로세스를 처리할 수 있는 전용 Tasklet이라고 보면 된다.
이 Tasklet은 스프링 배치가 기본적으로 제공한다.
*Chunk기반의 프로세스는 ItemReader, ItemProcessor, ImteWriter를 사용해서 처리한다.
*Chunk의 원리 자체가 최종적으로 Tasklet이 수행이되면 commit을 하게 된다.
[스프링배치 도메인 이해 - ExecutionContext]
1. 기본 개념
-프레임워크에서 유지 및 관리하는 키/값으로 된 컬렉션으로 StepExecution 또는 JobExecution
객체의 상태(state)를 저장하는 공유 객체
-DB에 직렬화 한 값으로 저장됨 - {"key" : "value"}
-공유범위
-Step 범위 - 각 Step의 StepExecution에 저장되며 Step 간 서로 공유 안됨
(ExecutionContext가 각 Step에 StepExecution에 저장된다.)
(이때 Step에 저장되는 ExecutionContext는 Step간 서로 공유 안됨)
-Job 범위 - 각 Job의 JobExecution에 저장되며 Job간 서로 공유 안되며 해당 Job의 Step 간 서로 공유됨
-Job 재 시작시 이미 처리한 Row 데이터는 건너뛰고 이후로 수행하도록 할 때 상태 정보를 활용한다.
*ExecutionContext는 상태를 저장하는 공유객체이기 때문에 공유할 데이트를 활용하는데 사용하지만
보통 스프링 배치에서는 Job이 재시작 될 때 실패할 그 당시에 데이터들을 ExecutionContext에 저장해 놓고
그 Job을 다시 시작 할 때 ExecutionContext에 저장해 놓은 값을 참조해서 이미 처리한 데이터는 건너뛰고
실패한 데이터 부터 수행하도록 할 때 상태정보를 활용한다.

*Tasklet이나 StepListener 클래스에서 StepExecution을 통해서 JobExecution을 꺼내 사용할 수 있습니다.
JobExecution에서 ExecutionContext를 꺼낼 수 있습니다.

*Tasklet을 만들어서 Tasklet에 인자로 주어지는 StepContribution, ChunkContext라는 인자 값을 활용해서 StepExecution을 뽑아 낼 것이다.
*Contribution 클래스를 활용하든 CunkContext 클래스를 활용하든 각각의 StepExecution은 동일하게 참조가 가능하다.
-contribution.getStepExecution().getJobExecution().getExecutionContext();
-chunkContext.getStepContext().getStepExecution().getJobExecution().getJobInstance().getJobName()
[스프링배치 도메인 이해 - JobRepository]
1. 기본개념
-배치 작업 중의 정보를 저장하는 저장소 역할
-Job이 언제 수행되었고, 언제 끝났으며, 몇 번이 실행되었고 실행에 대한 결과 등의 배치 작업의 수행과
관련된 모든 meta data를 저장함
-JobLauncher, Job, Step 구현체 내부에서 CRUD 기능을 처리함
*JobLauncher, Job에서 JobInstance, JobExecution 등 또 Step도 StepExecution, StepExecutionContext와 같은 이런 여러가지 메타 데이터를 저장하는 시점마다 CRUD 기능들이 작동하는데 이때 JobRepository클래스가 각각의 단계마다 이런 데이터를 저장하고 업데이트 하고 조회하는 역할을 담당하고 있습니다.JobRepository는 메타데이터들을 저장하는 저장소 역할을 한다.


2.JobRepository 설정
-@EnableBatchProcessing 어노테이션만 선언하면 JobRepository가 자동으로 빈으로 생성됨
-BatchConfigurer 인터페이스를 구현하거나 BasicBatchConfigurer를 상속해서 JobRepository 설정을
커스터마이징 할 수 있다.
-JDBC 방식으로 설정 - JobRepositoryFactoryBean
-내부적으로 AOP 기술을 통해 트랜잭션 처리를 해주고 있음
-트랜잭션 isolation의 기본값은 SERIALIZEBLE로 최고 수준,
다른 레벨(READ_COMMITED, REPEATABLE_READ)로 지정가능
-메타테이블의 Table Prefix를 변경할 수 있음, 기본 값은 "BATCH_"임
-In Memory 방식으로 설정 - MapJobRepositoryFactoryBean
-성능 등의 이유로 도메인 오브젝트를 굳이 데이터베이스에 저장하고싶지 않을 경우
-보통 Test나 프로토타입의 빠른 개발이 필요할 때 사용

[스프링배치 도메인 이해 - JobLauncher]
1. 기본개념
-배치 Job을 실행시키는 역할을 한다.
-Job과 Job Parameters를 인자를 받으며 요청된 배치 작업을 수행한 후 최종 client에게 JobExecution을 반환함
-스프링 부트 배치가 구동이 되면 JobLauncher 빈이 자동 생성 된다.
-Job 실행
-JobLauncher.run(Job, JobParameters)
-스프링 부트 배치에서는 JobLauncherApplicationRunner 가 자동적으로 JobLauncher을 실행시킨다.
-동기적 실행
-taskExecutor를 SyncTaskExecutor로 설정할 경우(기본 값은 SyncTaskExecutor)
-JobExecution을 획득하고 배치 처리를 최종 완료한 이후 Client에게 JobE xecution을 반환
-스케줄러에 의한 배치처리에 적합 함 - 배치처리시간이 길어도 상관이 없는 경우
-비 동기적 실행
-taskExecutor가 SimpleAsyncTaskExecutor로 설정할 경우
-JobExecution을 획득한 후 Client에게 바로 JobExecution을 반환하고 배치처리를 완료한다.
-HTTP 요청에 의한 배치 처리에 적합함 - 배치처리 시간이 길 경우 응답이 늦어지지 않도록 함
*taskExecutor은 실제로 JobLauncher가 Job을 수행할 때 내부적으로 가지고 있는 속성입니다.
taskExecutor 내에서 Job이 수행된다.


*ExitStatus는 JobExecution에 들어 있는 속성이다.

*JobLauncherApplicationRunner 클래스는 ApplicationRunner 인터페이스를 구현하고 있다.
ApplicationRunner 인터페이스는 스프링 부트에서 제공하는 인터페이스이다.
ApplicationRunner 인터페이스는 스프링 부트가 초기화가 되면 ApplicationRunner 인터페이스를 구현한
구현체의 Run메소드를 호출 해주는 역할을 한다.
'SpringBatch' 카테고리의 다른 글
| 스프링 배치 실행 - start() / next() (0) | 2022.06.21 |
|---|---|
| 스프링 배치 실행 - 개념 및 API 소개 (0) | 2022.06.18 |
| 스프링 배치 실행 - JOB (0) | 2022.05.31 |

